Convert GPB Notes to Markdown Files
为了写上一篇 Bird Day 的笔记因而又一次想把 Google Play Books 的 notes 转换成 Markdown,但实在是搞不定批量自动化转换 Google Docs,于是用了个笨方法,先用 Google Docs 的下载功能,格式选 Markdown。再用 Python 脚本跑一遍这个 md 文件处理格式,前后对比如下:
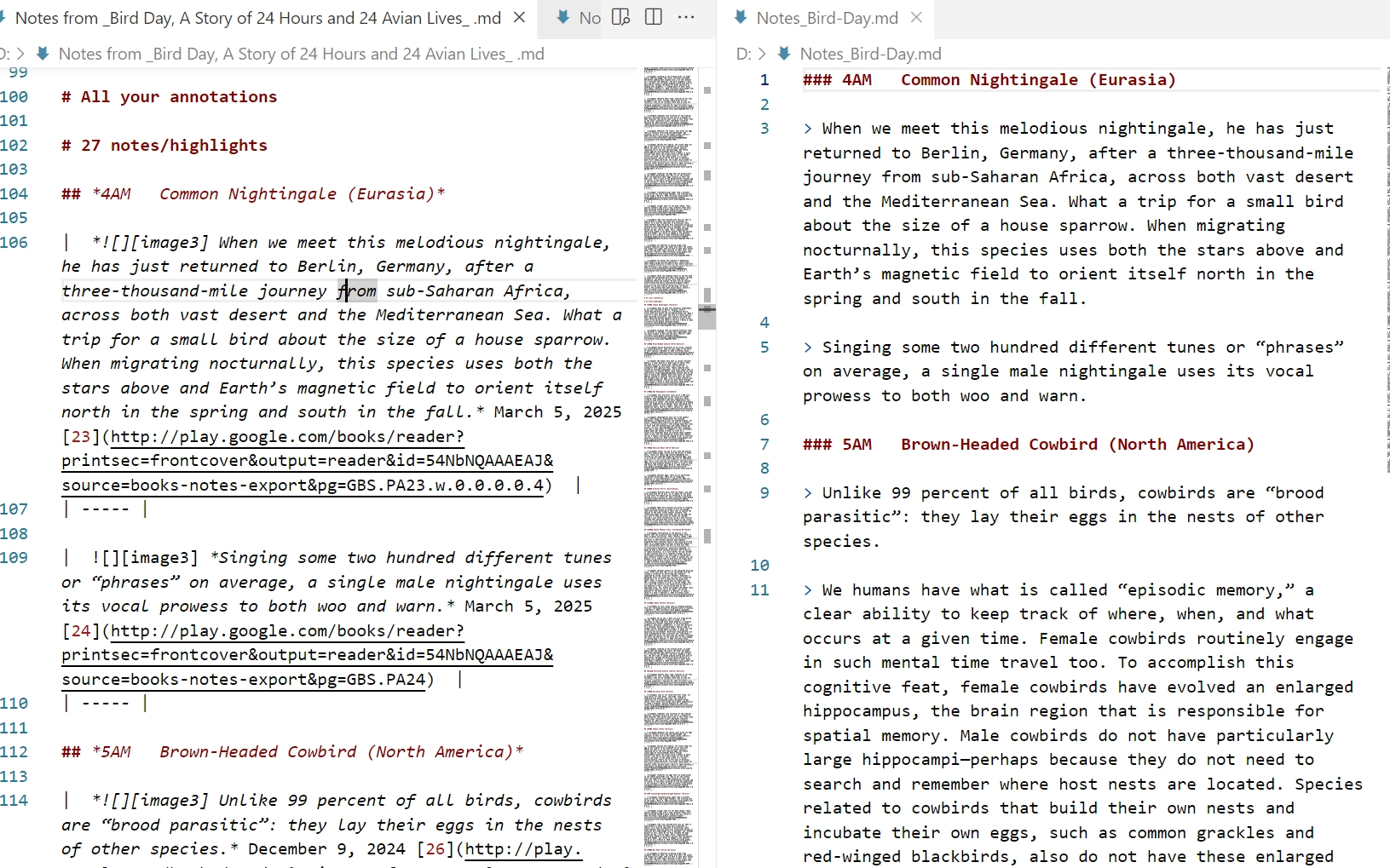
为什么我又开始搞这种东西,头大。非常后悔没好好学 regex(但这东西平时不用那就分分钟忘也不能怨我吧),而且也没注意到 Google 这个该死的文件居然每个章节下面第一段的格式和后面的摘抄是不一样的,折腾语法折腾了好久,最后的解决方案也还是不灵巧,很挫败,只能这么凑合着用。把脚本内容在博客存个档,后续再改进也方便找。
我不需要区分各颜色标注,就直接从文档里的 All your annotations 部分开始转换。想法部分也没有保留,因为通常我只是写一些关键词,并不是完整的句子,不需要体现在摘录里。
这个脚本只做下面三件事:
- 转换章节标题
- 转换摘录格式
- 设置转换后的文件名格式
import re
import os
def format_output_filename(input_filename):
# Extract content between underscores and comma if present
base_name = os.path.splitext(input_filename)[0]
match = re.search(r"_(.*?)(?:,|$)", base_name)
if match:
return f"Notes_{match.group(1).replace(' ', '-')}.md"
parts = base_name.split("_")
if len(parts) > 1:
return f"Notes_{parts[0]}-{parts[1]}.md"
return f"Notes_{parts[0]}.md"
def process_md_file(input_path, output_folder):
with open(input_path, "r", encoding="utf-8") as file:
content = file.readlines()
# Step 1: Find the start index of annotations section
start_idx = next((i for i, line in enumerate(content) if line.strip() == "# All your annotations"), None)
if start_idx is None:
raise ValueError("No '# All your annotations' found in the file.")
# Step 2: Keep only content below '# All your annotations'
content = content[start_idx + 1:]
output_lines = []
# Step 3: Regular expression patterns
title_pattern = re.compile(r"## \*(.*?)\*") # Title
annotation_pattern_1 = re.compile(r"\|\s*\*!?\[\]\[image\d*\]\s*(.*?)\*\s*.*?\[\d+\]\(http.*?\)\s*\|")
annotation_pattern_2 = re.compile(r"\|\s*!?\[\]\[image\d*\]\s*\*?(.*?)\*\s*.*?\[\d+\]\(http.*?\)\s*\|") # Annotations
current_title = None
annotations = []
# Step 4: Process the file content
for line in content:
title_match = title_pattern.match(line)
annotation_match = annotation_pattern_1.search(line) or annotation_pattern_2.search(line)
if title_match:
# Save the previous title's annotations before moving to a new one
if current_title and annotations:
output_lines.append(f"### {current_title}\n\n" + "\n\n".join(annotations) + "\n")
# Start a new title section
current_title = title_match.group(1).strip()
annotations = [] # Reset annotations for the new title
elif annotation_match:
annotation = annotation_match.group(1).strip().replace(r"\!", "!")
annotations.append(f"> {annotation}") # Add the annotation
# Save the last collected annotations
if current_title and annotations:
output_lines.append(f"### {current_title}\n\n" + "\n\n".join(annotations) + "\n")
# Step 5: Remove any image references or extra content at the end
output_text = "\n".join(output_lines)
output_text = re.sub(r"\[image\d*\]:.*", "", output_text)
# Step 6: Format output filename
input_filename = os.path.basename(input_path)
output_filename = format_output_filename(input_filename)
output_path = os.path.join(output_folder, output_filename)
# Step 7: Save output to file
os.makedirs(output_folder, exist_ok=True)
with open(output_path, "w", encoding="utf-8") as file:
file.write(output_text)
print(f"Processed file saved at: {output_path}")
# Example usage
input_md_file = "input_file_path"
output_directory = "output folder"
process_md_file(input_md_file, output_directory)
搞完发现 Github 上有人写过类似的 Google Books highlights and notes extractor ,应该会比我的好用(吧)。怎么感觉我又是努力努力白努力(无能狂怒 ing)。
Comments