一些偷懒的豆瓣书影音同步流程
喊了一万遍豆瓣已死和逃离豆瓣,可它还是简中世界最重要的书影音数据集中地。从 2008 年用豆瓣,这些年几乎每一本读过的书、看过的电影都在豆瓣标记过,其他数据无所谓,这长达十几年的档案还是割舍不下。最早豆瓣有封禁苗头时我陆续用 豆坟 导出过几次数据,但这只是一堆 excel 表格,静止的数据并没有价值。期间用了几天 Goodreads,也试图用 neodb 取代豆瓣,但豆瓣最重要的一点:关注友邻的精神食粮动态,目前仍没有对手。因此我在挣扎之下处于半弃瓣状态,仅用它做标记,不再发言。
现在我的书影音档案在四个地方:豆瓣、notion、blog 以及 neodb。
豆瓣
纯手动,读完/看完后挨个标记。
Notion
Notion 同步用的是在长毛象看到的 教程 。
原理是通过 GitHub Action 定期抓取用户的豆瓣 rss feed 来获取更新,缺点是每次只能抓取最近 10 条记录,此前数据只能手动导入(用豆坟或油猴插件一次性获取)。而豆坟导出的数据不含海报信息,这样一来从前的记录无法显示图片,总觉得略微遗憾。notion 本身的显示页面也不是很灵活,加载还很慢,得不停点击 load more 才会继续显示,我单纯是因为不需要手动就姑且当多个备份仓库了。
实现成果如下图。
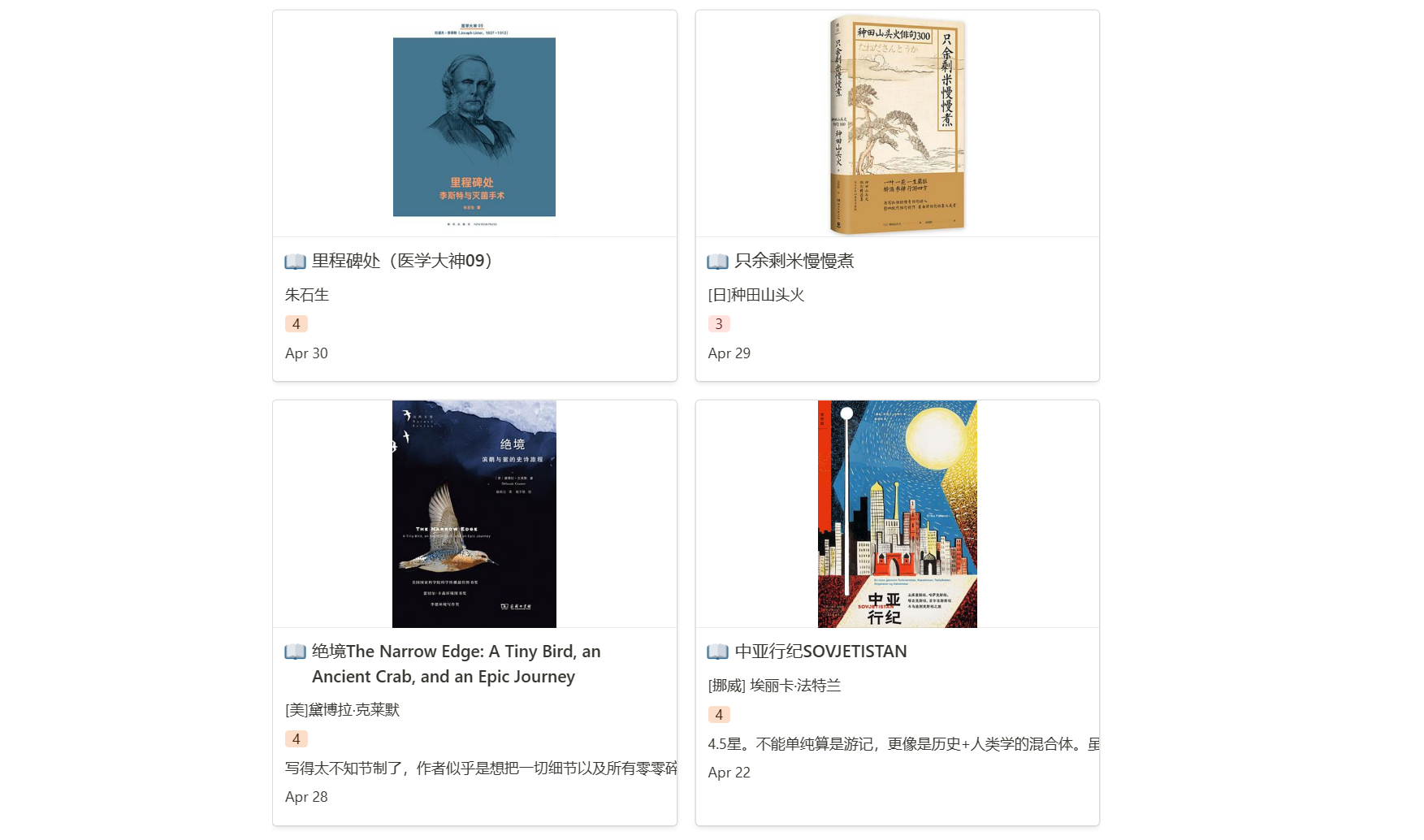
Blog
同样是全自动,只需初始设定完毕后续就无需手动操作。
原理是使用 GitHub Action 定期抓取用户豆瓣书影音记录,在个人 GitHub 仓库里生成对应 csv 文件。优点是第一次启用就能获取全部历史数据,后续的自动更新也没有上面的十条数量限制,还能自行编辑 csv 文件增加新条目,比如被豆瓣和谐的那些。缺点是导出的数据居然缺了 ISBN!等我好好学习完 GitHub Action 就自己重写一个(遥遥无期的 flag )。
但获取数据只是第一步,将数据可视化还需要更多折腾。作者提供了两个途径,一是同步到 blog,二是同步到 notion 。
同步到 blog 具体就是往自己的静态博客里加几个网页,再写对应的 CSS ,让 csv 文件能够以图片墙形式显示,我抄的这个 「电影 / 阅读」页面,顶! , 略微做了点改动。
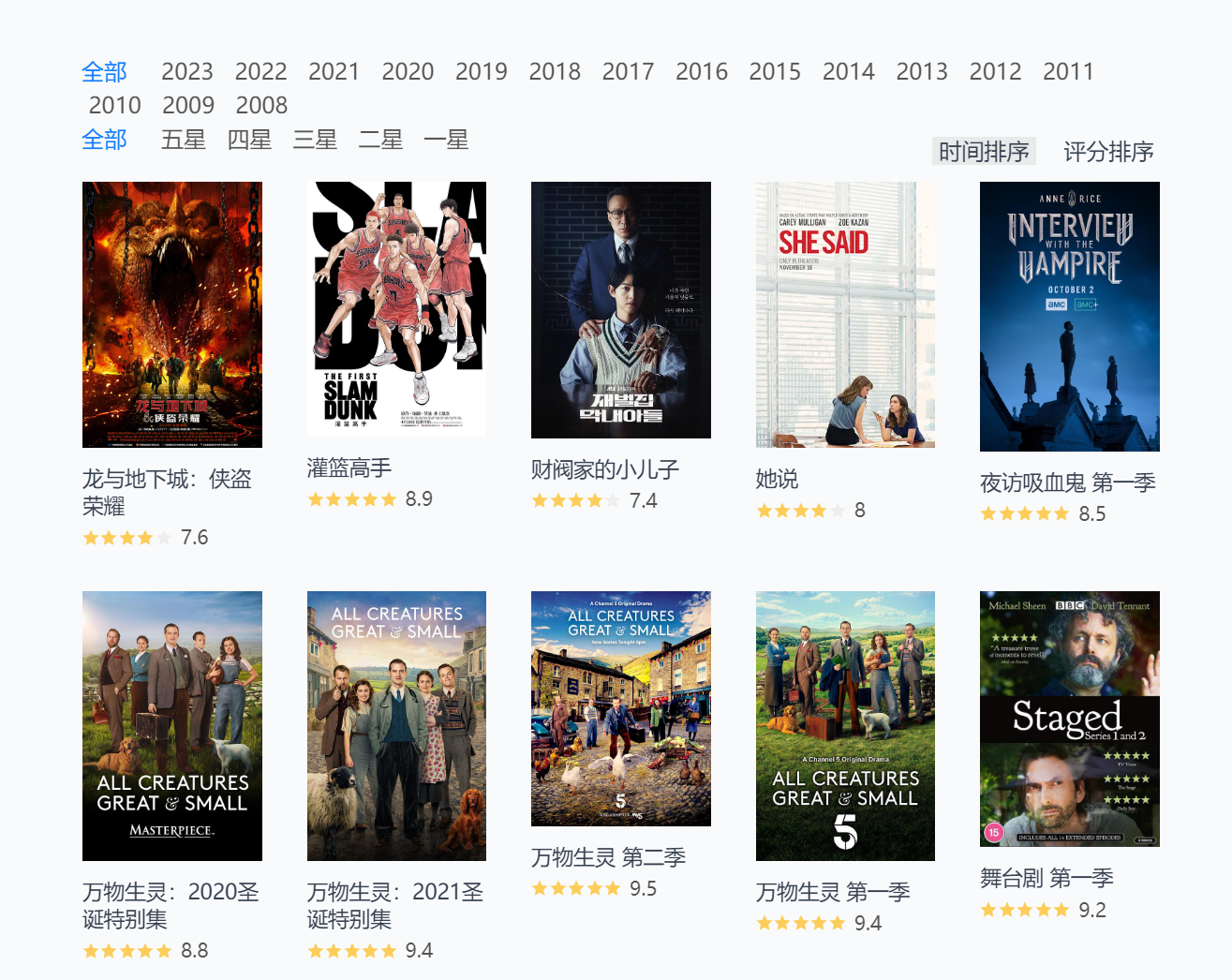
(其实还有点问题,我的 blog header 太宽挡住了一部分页面,网页版的我改掉了,但没对手机页面进行适配,就这么先凑合着吧!)
同步到 notion 原作者也给了教程,我试了下他给的 notion template 导入数据有点问题,而我实在是对 notion 的编辑逻辑感到苦手,不想自己一个个设置 block 属性,遂放弃。如果不在意缺少 ISBN 和愿意自己设置 notion template,可以略过上面的 rss 同步方式直接选用这个。
Neodb
懒得每次把豆瓣标记内容复制一遍到 neodb ,幸好它也支持数据导入(豆坟格式的 excel 表格),我因为很久之前就卸载了豆坟插件,所以用 python + pandas 把上一步 blog 里的 csv 文件筛选关键字段转换成 excel ,每隔一两个月导入一次。
以读过为例,大概如下图,呃相当粗糙的代码。总之有这几项就能成功导入。
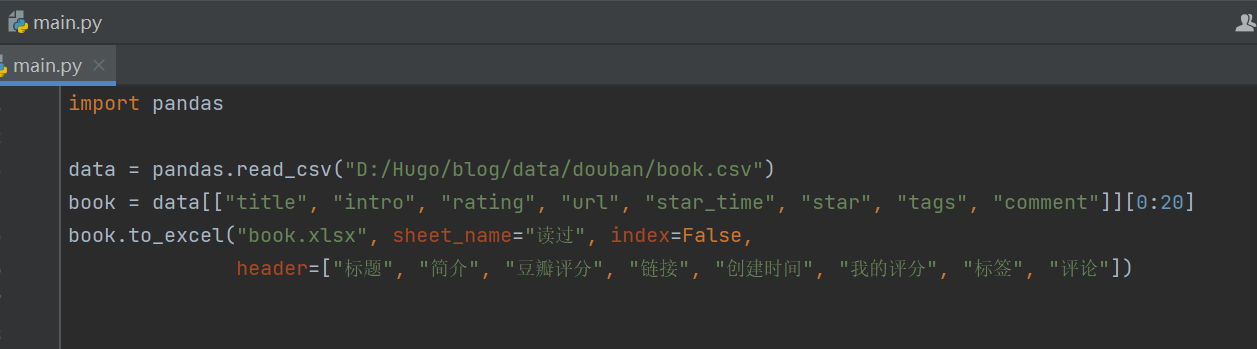
其实 neodb 既然有开放 api,那理论上应该也能用 GitHub Action 自动获取更新,那样就可以彻底放弃豆瓣,把 neodb 作为首次标记渠道,再同步到 notion 或是 blog 。可我还没打定主意彻底转向它,也怕 neodb 作为网友自发维护的项目哪天就停止运行了,豆瓣虽然一直半死不活的但应该还能再苟一阵子……吧?当然更重要的是我只读了遍 GitHub Action 官方文档,大概了解流程和运作原理,根本没写过,等哪天实在需要再说。
2023.07.17 update:
上面提到的 notion 同步工具现在增加了 neodb 同步,所以也实现了自动化,再也不用手动导入啦。
Goodreads
顺便一提 Goodreads,它也接受导入,既然手头有这么多渠道的数据,就折腾下试试看。
首先根据这个链接 Import/Export Books to My Account | Goodreads 查看 sample 文件,最不可或缺的是 ISBN,其他其实只要评分、评论、标记时间以及读过状态就够了。我只选择了以下几栏。
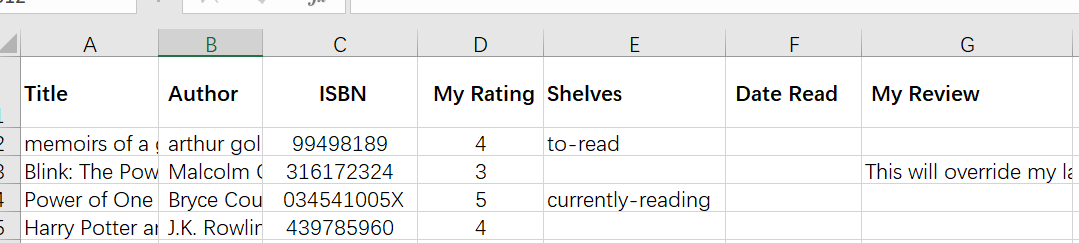
试验了下,上半年的 60 本书,成功导入 51 本,剩余无法识别,应该是因为有些中文书暂时没有条目。失败比例还是颇高,我大概率会放弃这个平台了。
最后,对自己的灵魂质问,我是闲出问题来了吗?写这个干嘛?算了,就当给自己存个档吧!
Comments